
© Markus Spiske via Unsplash
L'encodage
Développeur ou non, vous avez sûrement vu plus d’une fois ce type d’étrangetés sur un site web, ou dans un fichier de votre ordinateur. Surgi de nulle part, un mot contenant é en lieu et place d’un caractère accentué (été devient été par exemple).
Je me suis posé la question de l’origine de ces caractères bizarres bien avant de m’intéresser au développement, mais j’étais encore chimiste à l’époque (personne n’est parfait) et n’ai pas cherché l’explication. Je l’ai récemment obtenue au cours d’une conférence donnée au BreizhCamp par Guillaume Collic dont l’enregistrement est disponible ici.
Répondre à cette question implique d’aborder une notion fondamentale en informatique, qu’est-ce que l’encodage ?
Définition
Quand on cherche une définition de la notion d’encodage sur internet, on peut trouver ceci :
- Action de coder un texte, des données informatiques (dictionnaire Larousse)
- Action de transcrire des données vers un format ou un protocole donné (Wikipedia)
Encoder un message, des données, c’est quelque part traduire dans un autre “alphabet”, un autre “langage” un texte, un nombre, une donnée.
Des caractères et des bits
Avant d’aborder l’une des premières tentatives d’encodage, arrêtons-nous sur la notion de bits. Un bit peut prendre 2 valeurs distinctes, 0 et 1. Avec 1 bit, vous avez donc 2 choix, 1 et 0. Ajoutez un bit supplémentaire et vous doubles le nombre de combinaisons. Comme le montre le tableau suivant, les possibilités s’étendent considérablement à chaque ajout de bit.
| Nombre de bits | Nombre de combinaisons | combinaisons |
|---|---|---|
| 1 | 2 | 1 0 |
| 2 | 4 | 11 10 01 00 |
| 3 | 8 | 111 110 101 100 011 010 001 000 |
| 4 | 16 | 1111 1110 1101 1100 1011 1010 1001 1000 0111 0110 0101 0100 0011 0010 0001 0000 |
Après ce focus sur les bits et la combinaison de bits, revenons à l’une des premières tentatives d’encodage binaire, le code Baudot.
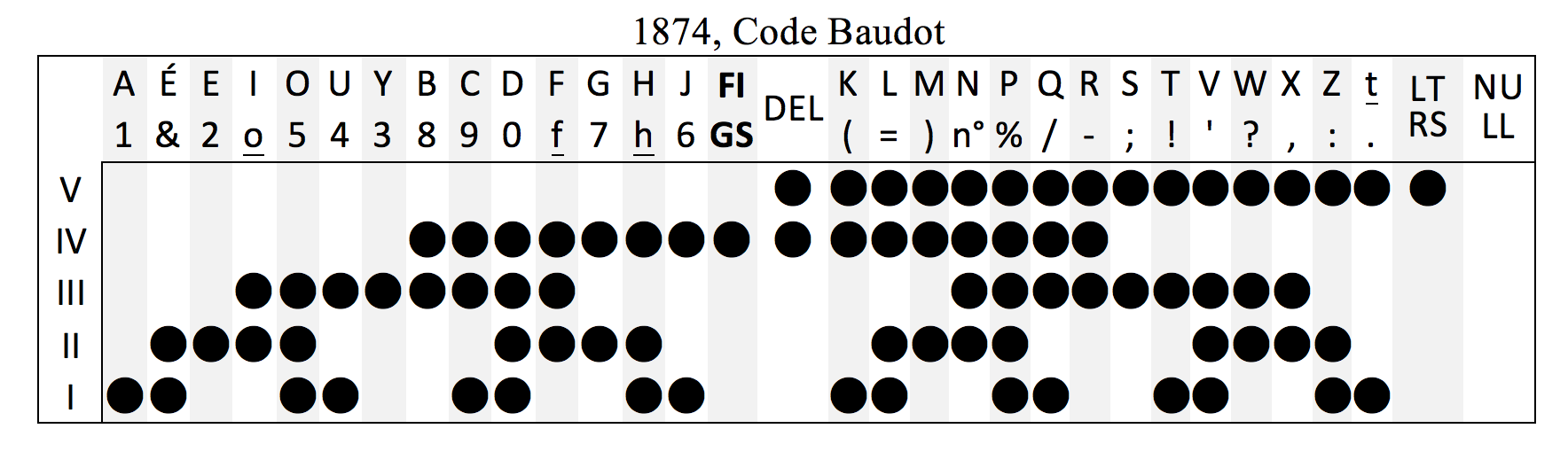
Avant l’informatique, le code Baudot (1874)
Le code Baudot est un lointain ancêtre des méthodes d’encodage que nous utilisons de nos jours. Destiné au télégraphe, il utilisait des rubans perforés afin d’encoder chaque caractère, sur 5 bits.
Il ne disposait donc que de 32 caractères, suffisant pour les lettres mais pas pour les chiffres, les symboles (mathématiques, ponctuation). Pour pallier ce problème, on ajoute un deuxième jeu de caractères destiné à ces symboles, et 2 caractères spéciaux permettent d’indiquer quand on change de jeu de caractères.
Si on prend un message comme “Hello World !” et qu’on le traduit en Morse, on obtient ceci :
H E L L O W O R L D FIGS !11010 010000 11011 11O11 11100 00000 01101 11100 00111 11011 11110 00001 10101Le télégraphe utilisait des séries de sons, un bruit court correspondait à un point, un bruit long à un tiret.
Pour la personne “au bout du fil”, entendre la série de sons indiquée plus haut tout en ayant une table de correspondance comme la suivante, permettait de restituer le message.
Cela ne vous aura pas échappé, la technologie a évolué depuis le télégraphe, et nous sommes entrés depuis quelques décennies dans l’ère de l’informatique et de l’échange de données permanent. Le Morse c’était pratique, mais uniquement adapté aux langues latines (langues écrites avec l’alphabet que nous connaissons), et très limité en termes de quantité de données rapportée au temps de transmission.
Les prémices de l’informatique : l’ASCII (1963)
La naissance de l’informatique nous a amenés à penser de manière binaire, les premiers ordinateurs fonctionnant avec des cartes perforées “lues” par les premiers ordinateurs, avec un trou pour 0 et pas de trou pour 0. Mémoriser des informations revenait donc à faire ingérer à des ordinateurs des séries de 0 et de 1. Mais comment traduire une langue écrite, des nombres, des symboles en 0 et en 1 ? Il devient nécessaire de créer un encodage permettant de réaliser la transformation de données en suites de 0 et de 1.
Par rapport au code Baudot, l’ASCII utilise 2 bits supplémentaires, montant donc à 128 caractères, qui permettent d’encoder :
- les lettres de l’alphabet latin (majuscules et minuscules)
- les chiffres arabes
- les symboles de ponctuation
- des symboles mathématiques
Ce que je viens de décrire correspond à l’American Standard Code for Information Interchange (Code américain normalisé pour l’échange d’informations). Bien entendu, dit comme ça, je doute que ça vous évoque quoique ce soit ! Et pourtant, l’ASCII, vous en avez sûrement déjà entendu parler.
Voici la table ASCII telle qu’on la connaît, avec l’ensemble des caractères qu’elle contient.
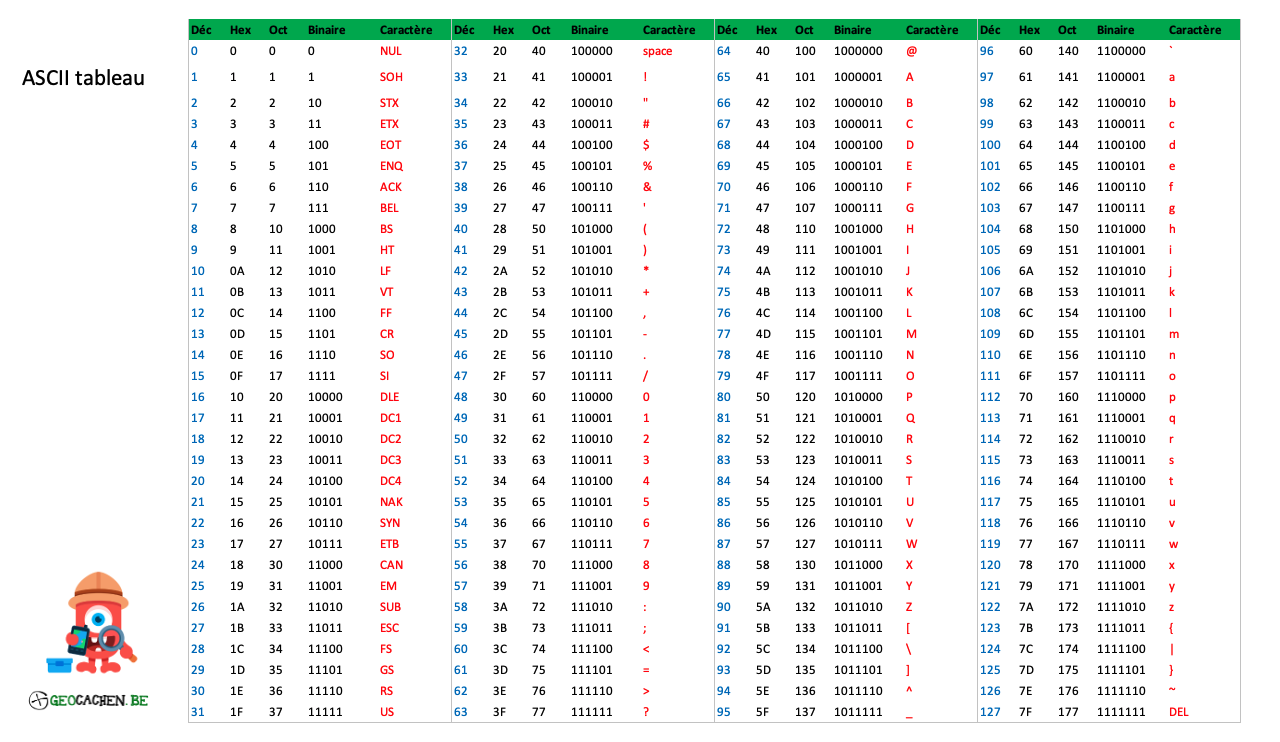
On doit cette norme à l’ISO (Organisation Internationale de Normalisation, oui oui, c’est normal que le nom ne corresponde pas au sigle), et la première version de la norme ASCII est sortie en 1963.
Si on prend le même message que précédemment et la notation décimale ASCII, le message encodé deviendra une série de nombres.
H E L L O W O R L D72 69 76 76 79 32 87 79 82 76 68Les limites de l’ASCII
Quand nous avons décrit les éléments contenus dans la norme ASCII, nous avons parlé de plusieurs ensembles de caractères, dont l’alphabet latin, majuscules et minuscules incluses. Mais pour les langues qui possèdent des caractères accentués, nous sommes coincés.
Impossible de représenter ces caractères qui n’existent tout simplement pas dans la norme ASCII. On a donc une norme adaptée aux anglophones, mais qui excluent un grand nombre de langues possédant ces fameux caractères accentués.
Il a donc fallu trouver une solution pour intégrer plus de caractères.
Au-delà de l’ASCII : l’ISO 8859 (1987)
Si on suit la logique présentée au début de l’article, ajouter un bit aux 7 déjà utilisés pour encoder les caractères double la capacité d’encodage, passant de 128 à 256 caractères possibles. On arrive cette fois-ci à la norme ISO 8859, qui cette fois-ci se découpe en 16 parties afin de couvrir un très grand ensemble de langues :
- ISO 8859-1 : latin-1 : européen occidental
- ISO 8859-2 : latin-2 : européen central
- ISO 8859-3 : latin-3 : européen du sud
- ISO 8859-4 : latin-4 : européen du nord
- ISO 8859-5 : cyrillique
- ISO 8859-6 : arabe
- ISO 8859-7 : grec
- ISO 8859-8 : hébreu
- ISO 8859-9 : latin-5 : turc
- ISO 8859-10 : latin-6 : nordique : révision du latin-4
- ISO 8859-11 : thaï
- ISO 8859-12 : latin-7 : balte
- ISO 8859-14 : latin-8 : celtique
- ISO 8859-15 : latin-9 : révision du latin-1
- ISO 8859-16 : latin-10 : européen du sud-est
Oui il y a un manque, l’ISO-8859-13 a été abandonné à l’aube des années 2000.
On peut constater qu’une grande diversité de langues est désormais prise en compte, avec des jeux de caractères larges et exhaustifs. En revanche, on reste globalement limité aux pays occidentaux. De fait, l’Asie est quasi-inexistante à l’exception du thaï, malgré le fait que l’écrasante majorité de l’humanité se trouve précisément en Asie.
Certaines langues asiatiques présentent la particularité d’être des langues idéographiques, un caractère représentant une idée, qui, combinée à une ou plusieurs autres, va constituer un mot. On ne parle plus d’un alphabet avec une petite trentaine de caractères, mais de plusieurs milliers de symboles à prendre en compte. Unicode est arrivé pour régler ce problème.
La révolution Unicode (1991)
Ce nouvel encodage est né avec la volonté d’accorder les méthodes d’encodage nationales, et d’éviter les malentendus inhérents à certains types de symboles, notamment les symboles monétaires.
L’encodage Unicode a pour but d’uniformiser l’encodage de la totalité des symboles utilisés dans le monde, indifféremment de la langue, de la culture etc. Là où nous parlions de quelques centaines de caractères pour l’ASCII, on arrive ici à 1 114 112 caractères possibles.
Cette fois, nous n’avons pas une puissance de 2, car l’organisation des tables Unicode est différente des autres, les caractères sont répartis en 17 plans, chaque plan possédant 2^16 ou 65536 caractères.
En lieu et place d’un encodage sur 8 bits, ou 1 octet, on a mis au point un encodage sur 1 à 4 octets, totalement rétrocompatible avec l’ASCII. C’est à dire que les caractères de 0 à 127 sont rigoureusement les mêmes qu’en ASCII, mais qu’à partir du caractère 128 on ajoute un octet supplémentaire. Quand on arrive au 8ème chiffre de ce second octet on passe au troisième, et on répète encore l’opération pour arriver au 4ème octet.
Sans rentrer dans les détails, à la différence de l’UTF-8 qui possédaient toutes les mêmes codes (de 0 à 127), ce qui pouvait causer des problèmes, un dollar devenant une livre sterling par exemple, toutes les parties des tables d’encodage Unicode ont des codes uniques. Ces codes vont de U+0000 à U+10FFFF, en hexadécimal cette fois.
Traduisons le message rituel :
H E L L O W O R L DU+0048 U+0045 U+004C U+004C U+004F U+0020 U+0057 U+004F U+0052 U+004C U+0044Un peu plus lourd que la notation ASCII, mais cette fois-ci aucun caractère ne changera d’un pays à un autre.
Dans les faits, il existe plusieurs manières d’utiliser l’encodage Unicode, avec les encodages UTF-8, UTF-16 et UTF-32. Arrêtons-nous sur l’UTF-8, le plus couramment utilisé à l’heure actuelle.
| Critère | UTF-8 | UTF-16 | UTF-32 |
|---|---|---|---|
| octets par caractère | 1 - 4 | 2 - 4 | 4 |
| compatibilité ascii | parfaite | moyenne | mauvaise |
| mémoire (langues latines) | faible | élevée | élevée |
| mémoire (langues asiatiques) | élevée | faible | élevée |
Si dans les années 2000 UTF-8 représentait 80% du web, à l’heure actuelle nous sommes à près de 98,3% du web.
Mais pourquoi ça déraille alors que c’est si efficace ?
Les dessous d’un raté
Parfois un “é” devient “é”. Pas de rapport entre les deux, mais pourquoi observe-t-on cette transformation ?
Un indice : tous les encodages n’utilisent pas le même nombre d’octets pour encoder un caractère.
Un autre ? Ce type de problème se produit souvent entre l’UTF-8 et l’ASCII.
Il faut regarder de plus près l’encodage d’un e accent aigu en UTF-8 : il est encodé sur 2 octets, comme ceci :
caractère : éUTF-8 : C3 A9 (écriture hexadécimale sur 2 octets)ASCII : Ã ©L’ASCII étant un encodage sur 1 octet, il n’est pas capable de comprendre que les 2 octets qu’on lui envoie définissent un seul et même caractère, et les interprète donc comme 2 caractères distincts, en l’occurrence un A majuscule tilde (C3) et un C commercial (A9).
Lorsque vous voyez ces caractères, ou encore le fameux point d’interrogation dans un losange noir �, c’est que l’un des caractères de votre texte n’a pas été reconnu. Vous êtes donc devant un problème d’encodage !
En réalité, vous avez ouvert un fichier initialement encodé en UTF-8 avec un encodage ASCII. Comme UTF-8 et ASCII sont différents, certains caractères posent problème, notamment ceux qui sont encodés en UTF-8 sur plusieurs octets !
Et en développement, pourquoi on doit s’y intéresser ?
En développement, l’encodage des données est la première chose qu’on vous demande lorsque vous créez une base de données. Vous devez choisir votre encodage en fonction de vos besoins. Nul besoin d’utiliser de l’UTF-32 quand de l’UTF-8 latin-1 peut faire le travail. Votre base de données sera moins lourde et donc plus performante.
Conclusion
Indispensable à l’ère du web, il est important de prendre conscience des conséquences que peuvent avoir les erreurs d’encodage (avant Unicode, une facture américaine envoyée au Royaume-Uni affichait les prix en £ et non en $, sans changer le montant). Intéressant, non ?
Actuellement, un problème d’encodage peut empêcher la lecture d’un fichier, son interprétation par une application, et provoquer des erreurs dans une application. La prochaine fois que vous verrez un document ou un site web avec des caractères étranges, vous vous direz “C’est un problème d’encodage !”.
Cet article vous a plu ? Contactez-moi sur LinkedIn 😉 !


